Warp Dominates Terminal-Bench with 52% Success Rate, Outperforming Rivals
Summary
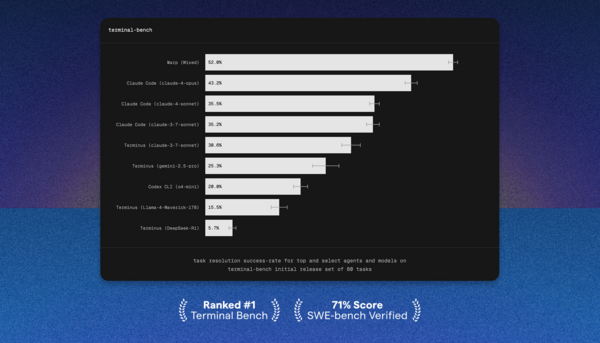
Warp achieves a remarkable 52% success rate on Terminal-Bench, outperforming rivals by 20% and securing the #1 spot through an optimal model fallback chain, agent control over long commands, and enforced todo list maintenance, utilizing Claude Sonnet 4 as primary and Claude Opus 4 as planning model.
Key Points
- Warp scored #1 on Terminal-Bench by achieving 52% success rate, 20% ahead of the next top submission
- Key factors contributing to Warp's success include optimal model fallback chain, granting agent control over long-running commands, and forcing agent to maintain a todo list
- Warp leverages Claude Sonnet 4 as primary model and Claude Opus 4 as planning model, with occasional fallback to other models like Gemini 2.5 Pro or OpenAI GPT-4.1