Breakthroughs in Transformer Models: DeepSeek V3, OLMo 2, and Gemma 3 Unleash New Capabilities
Summary
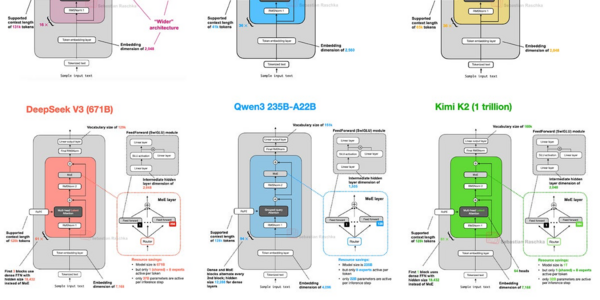
DeepSeek V3, OLMo 2, and Gemma 3 unleash groundbreaking transformer models, harnessing techniques like Multi-Head Latent Attention, QK-norm, and sliding window attention for improved efficiency, stability, and reduced memory footprint.
Key Points
- DeepSeek V3 uses Multi-Head Latent Attention and Mixture-of-Experts to improve efficiency
- OLMo 2 employs normalization layer placement and QK-norm for training stability
- Gemma 3 utilizes sliding window attention to reduce memory requirements