Reinforcement Learning Environments for AI Agents Are Rapidly Evolving, With Smarter Verifiers and Cheaper Infrastructure Reshaping What Models Can Learn
Summary
Reinforcement learning environments for AI agents are rapidly evolving, with smarter verifier designs, automated generation dropping costs to just $4 per environment, and emerging standards like Open Reward decoupling infrastructure from training — fundamentally reshaping what large language models can learn to do.
Key Points
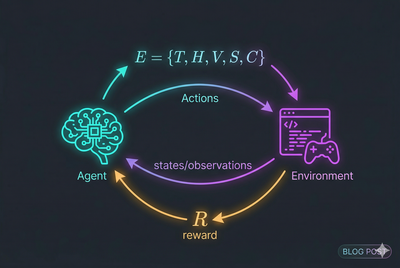
- Reinforcement learning environments for LLM agents consist of five critical components — tasks, agent harness, verifier, state management, and configuration — and these components, not model architecture alone, determine what an agent can actually learn to do.
- Verifier design is a central challenge, as programmatic checks are preferred over LLM-as-judge scoring, static rubrics get gamed by models, and techniques like evolving rubrics and deliberate noise injection during training produce agents that are more robust in real-world deployments.
- The RL environment ecosystem is rapidly maturing, with automated environment generation dropping costs to around $4 per environment, shared infrastructure like OpenReward serving 330+ environments as managed APIs, and standardized protocols like the Open Reward Standard emerging to decouple environments from trainers.