HeyGen's Avatar V Outperforms Rivals in Lip-Sync and Realism With New AI Video Avatar System
Summary
HeyGen's new Avatar V AI system outperforms all tested rivals in lip-sync accuracy and realism, using a Diffusion Transformer and novel Sparse Reference Attention to capture identity and dynamic behaviors, achieving win rates between 68.9% and 85.7% in human evaluations.
Key Points
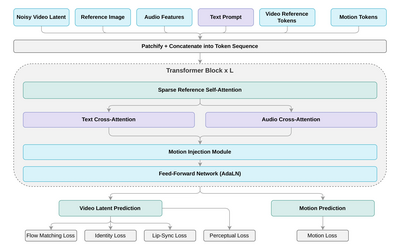
- Avatar V, built by HeyGen Research, is a video avatar generation system that uses a Diffusion Transformer with flow matching to condition directly on a user's full reference video token sequence, capturing both static identity features like skin texture and dental structure, and dynamic behavioral traits like talking rhythm and micro-expressions.
- A novel Sparse Reference Attention mechanism enables near-linear scaling with reference length, while a five-stage training curriculum progresses from general video pre-training through audio-driven synthesis, supervised fine-tuning, distillation, and RLHF alignment using GRPO and DPO to align outputs with human preferences.
- In objective and human evaluations against four competing systems, Avatar V achieves the highest lip-sync scores, face similarity, and ranks first across all six perceptual dimensions on a 5-point Likert scale, with pairwise win rates ranging from 68.9% to 85.7%, while the platform enforces strict consent verification and two-stage content moderation for all avatar creation.