GPT-5 Powered Agentic Search Smashes Baseline Scores But Hits Wall on Knowledge-Gap Tasks
Summary
GPT-5-powered agentic search systems are crushing baseline scores with an NDCG of 0.453 versus a 0.289 BM25 baseline on Amazon ESCI, but hit a hard wall when facing knowledge-gap tasks where LLMs cannot evaluate information they don't already know.
Key Points
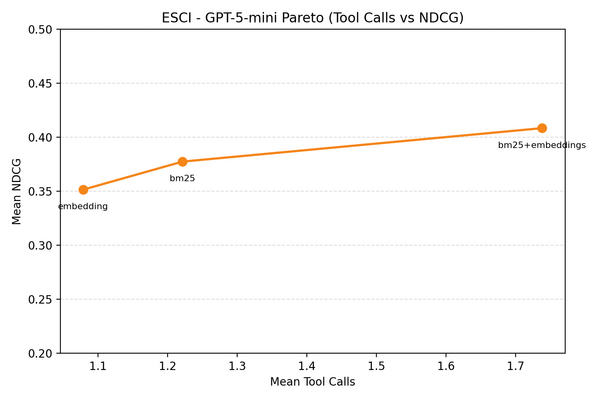
- Agentic search systems using basic retrieval tools like BM25 and embeddings are delivering significant performance gains, with GPT-5 driving both tools achieving an NDCG score of 0.453 compared to a 0.289 BM25 baseline on Amazon ESCI, requiring minimal custom tuning.
- Agents are boosting search quality by intelligently interpreting queries, issuing follow-up searches when initial results disappoint, and exploring diverse retrieval strategies, with performance improving further when agents are required to make multiple tool calls and use varied queries.
- A critical limitation emerges when agents tackle information retrieval rather than item-finding tasks, as LLMs cannot evaluate information they lack knowledge of, meaning traditional search stacks and 'Deep Research' approaches remain essential for knowledge-gap scenarios.