Rapid-MLX Launches as Fastest Local AI Engine for Apple Silicon, Beating Ollama by 4.2x
Summary
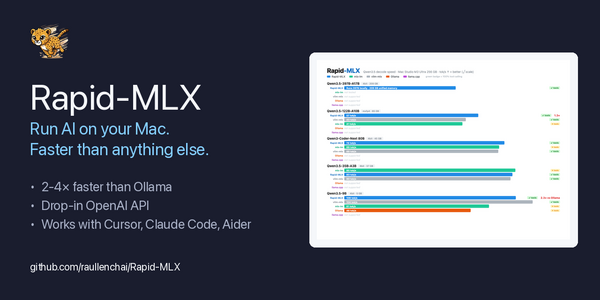
Rapid-MLX launches as the fastest local AI engine for Apple Silicon, running large language models up to 4.2x faster than Ollama with a Time to First Token as low as 0.08 seconds, offering full OpenAI API compatibility and support for tools like Cursor, Claude Code, and models ranging from compact to 158B parameters.
Key Points
- Rapid-MLX is an open-source local AI engine optimized for Apple Silicon, delivering speeds up to 4.2x faster than Ollama with a cached Time to First Token as low as 0.08 seconds, making it the fastest option for running large language models on Mac hardware.
- The engine supports 100% tool calling across 17 parser formats, features automatic tool call recovery, reasoning separation for chain-of-thought models, DeltaNet state snapshots for hybrid RNN architectures, and smart cloud routing for large-context requests — all through a drop-in OpenAI-compatible API.
- Compatible with popular AI coding tools including Cursor, Claude Code, and Aider, Rapid-MLX supports models ranging from Qwen3.5-4B on 16GB MacBooks to DeepSeek V4 Flash 158B on 256GB Mac Studio Ultra, and integrates seamlessly with frameworks like LangChain, PydanticAI, and smolagents.