Google Upgrades NotebookLM With Gemini 2.5, Web Search Integration, and Agentic Coding Capabilities
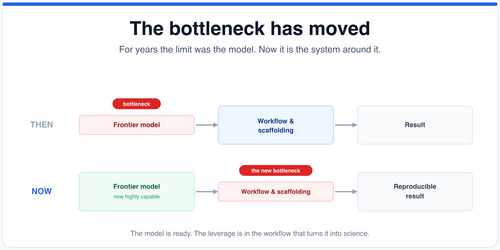
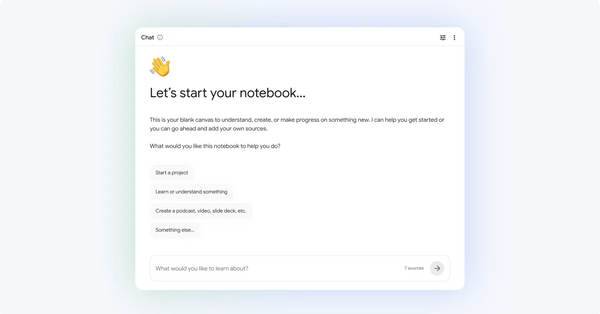
Google upgrades NotebookLM with Gemini 2.5, introducing web search integration that suggests relevant sources and agentic coding capabilities powered by the Antigravity platform, enabling notebooks to write and run code and export results in multiple formats.